Motivation
Every agent that calls an LLM faces the same concerns: which model, what cost, what latency, is governance satisfied, has the decision been recorded? Solving this inline in every agent creates duplication, inconsistency, and ungoverned inference.
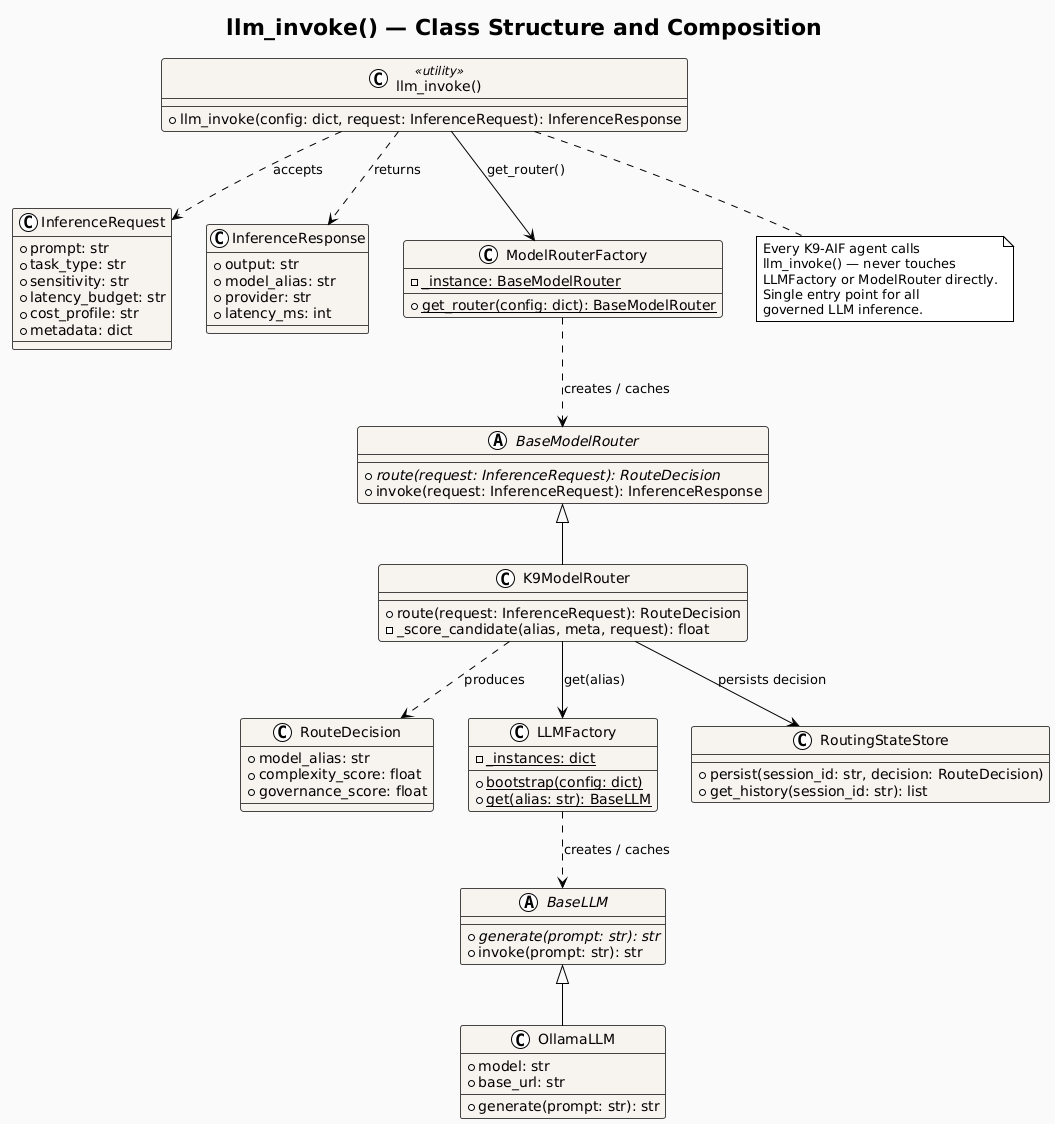
llm_invoke() is the single composition point. It routes through K9ModelRouter, resolves the model via LLMFactory, invokes the LLM, and persists the routing decision to the audit store — in one call. Agents are decoupled from all of it.
Structure
- Agent calls llm_invoke(config, InferenceRequest)
- ModelRouterFactory.get_router(config) returns cached K9ModelRouter
- K9ModelRouter.route(request) scores catalog models and returns RouteDecision
- LLMFactory.get(model_alias) returns cached OllamaLLM instance
- OllamaLLM.invoke(prompt) calls the model and returns raw response
- RoutingStateStore persists RouteDecision with latency and scores
- InferenceResponse returned to agent